



BERT

BERT
دليل مُفصّل ل BERT: نموذج NLP الثوري
- BERT، أو Bidirectional Encoder Representations from Transformers، واحد من أهم التطورات في معالجة اللغة الطبيعية (NLP) اللي قدمها باحثين جوجل سنة 2018. من وقت ما اتقدم BERT، وهو بقى معيار جديد لمهام ال-NLP، بفضل قدرته على فهم اللغة بدقة غير مسبوقة عن طريق تضمين السياق من الناحيتين. تعالوا نشوف إزاي BERT بيشتغل، عملية تدريبه، وليه بقى model قوي جدًا في deep learning وNLP.
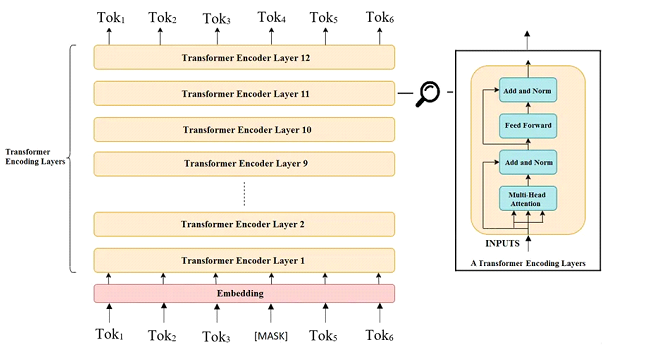
فهم بنية BERT.
- BERT مبني على هيكل Transformer، قوة Transformer الأساسية هي قدرته على استخدام Multi-head attention mechanism علشان يمسك العلاقات بين الكلمات في الجملة، بغض النظر عن موقعها، ومن غير الاعتماد على المعالجة التتابعية. قدرة المعالجة المتوازية دي بتخلي BERT فعال وقوي.
- على عكس النماذج التانية اللي بتعالج النص في اتجاه واحد (يا إما من الشمال لليمين أو من اليمين للشمال)، BERT بيشتغل بالاتجاهين. ده معناه إن BERT بياخد في اعتباره السياق من الناحيتين حوالين الكلمة في نفس الوقت، وده بيديله فهم أعمق للغة.
إزاي BERT بيتدرب
بتتقسم لمرحلتين:
مرحلة التدريب الأولي ومرحلة التعديل النهائي.
المرحلة الأولى:
التدريب الأولي
BERT بيتدرب في الأول على كمية كبيرة من نصوص غير معلمة، عشان يتعلم أنماط وعلاقات اللغة العامة. مرحلة التدريب الأولي ليها هدفين رئيسيين:
نموذج اللغة المقنعة (MLM):
علشان يشجع التعلم في الاتجاهين، BERT بيستخدم نموذج اللغة المقنعة (MLM). في مرحلة تدريب MLM، نسبة معينة (عادةً 15%) من الكلمات في كل جملة بتتحدد عشوائيًا وبتتغير لـ [MASK]. وبيحاول BERT يتوقع الكلمات المخبّية الأصلية باستخدام السياق المحيط.
مثال: لو عندنا الجملة “The quick brown fox jumps over the lazy dog”، كلمات زي “fox”، “the”، و”dog” ممكن تتغير لـ [MASK]، وده بيكون الشكل: “The quick brown [MASK] jumps over [MASK] lazy [MASK].” مهمة BERT إنه يتوقع الكلمات المخبّية بدقة بناءً على الكلمات الظاهرة. الأسلوب ده بيساعد BERT إنه يطور سياق من الناحيتين، لإنه بيعتمد على الكلمات اللي قبل وبعد علشان يعمل توقعات دقيقة.
التوقع للجملة التالية (NSP):
بالإضافة لهدف MLM،ا BERT بيتدرب كمان على التوقع للجملة التالية (NSP). مهمة NSP مصممة علشان تساعد BERT يفهم العلاقة بين جملتين، زي هل الجملة التانية تكملة منطقية للأولى ولا جملة عشوائية.
لكل زوج من الجمل، BERT بيتدرب على توقع إذا كانت الجملة التانية استمرار منطقي للأولى. المهمة دي بتحقق بإضافة رمز خاص [SEP] بين الجملتين ورمز تاني [CLS] في بداية تسلسل الإدخال. خلال التدريب، BERT بيتعلم يحلل التمثيل المخفي لرمز [CLS] ويعمل توقعات ثنائية عن استمرارية الجملة.
عن طريق تحسين الهدفين MLM وNSP في نفس الوقت، BERT بيتعلم مش بس الكلمات الفردية، لكن كمان العلاقات بين الجمل، وده بيقدي لفهم أقوى للغة.
المرحلة الثانية:
التعديل النهائي
- بعد التدريب الأولي، BERT بيدخل في مرحلة التعديل النهائي، وبيتم تكييفه على مهام معينة. على عكس مرحلة التدريب الأولي اللي بتستخدم بيانات غير معلمة، التعديل النهائي بيتطلب بيانات معلمة خاصة بالمهمة المطلوبة (زي text classification ،question answering ، أو sentiment analysis ).
- خلال التعديل النهائي، بنية BERT غالبًا بتتعدل شوية عشان تناسب احتياجات المهمة المحددة. على سبيل المثال، ممكن نضيف classification layer علشانsentiment prediction في مهمة sentiment analysis. ,و ال parameters الخاصة ب BERT المتدربة بتستخدم كقاعدة، وال model بيتدرب تاني على البيانات المعلمة لحد ما يوصل لأداء ممتاز في المهمة المطلوبة. الأسلوب ده بيسمح لـ BERT إنه يطبق الفهم العام للغة اللي اكتسبه خلال التدريب الأولي في مجموعة متنوعة من مشاكل ال NLP.
أهم مميزات BERT
قدرة BERT على التقاط تمثيلات غنية وثنائية الاتجاه للغة بتمكنه من التفوق في مهام ال NLP. ودي هي الأسباب اللي بتخلي BERT مميز:
⦁ سياق ثنائي الاتجاه: BERT بيمسك السياق من الناحيتين، وده بيديله فهم أعمق وأدق للغة مقارنة بال models أحادية الاتجاه.
⦁ كفاءة التعلم المنقولة: عملية BERT ذات المرحلتين (التدريب الأولي على اللغة العامة ثم التعديل النهائي على بيانات خاصة بالمهمة) بتسمح له إنه يؤدي كويس حتى مع الداتاسات الأصغر.
⦁ التعددية عبر المهام: BERT ممكن يتعدل ليتناسب مع مجموعة متنوعة من المهام، من التصنيف النصي للإجابة على الأسئلة، وده بيظهر مرونة عالية.
مثال عملي لـ BERT في التطبيق
خلينا نشوف إزاي BERT بيتعامل مع مهام اللغة بمثال بسيط.
لو دخلنا الجملة “The weather is nice, and [MASK] am planning to go for a walk.”، ا BERT ممكن يستخدم الكلمات المحيطة “weather is nice” و”am planning” عشان يتوقع إن الكلمة المفقودة هي “I”. القدرة دي على اعتبار السياق من الجانبين بتخلي BERT يفهم اللغة بطريقة مشابهة للبشر.
وبنفس الشكل، في مهمة NSP، لو اديناه الجمل “The cat sat on the mat” و”It started raining outside”، ا BERT المفروض يتوقع إن الجملتين دول مش جايين ورا بعض، لإنهم مش مرتبطين منطقيًا.
تأثير واستخدامات BERT
من وقت ما اتقدم، BERT بقى العمود الفقري لكثير من تطبيقات ال NLP، زي:
⦁ تحليل المشاعر (sentiment analysis ): تحديد المشاعر في تقييمات العملاء، منشورات السوشيال ميديا، والنصوص الأخرى.
⦁ الإجابة على الأسئلة (question answering): تشغيل أنظمة الأسئلة والإجابات زي chatbots اللي بتفهم وترد على الأسئلة بدقة.
⦁ تحديد الكيانات المسماة (NER): تحديد أسماء، تواريخ، وكيانات معينة تانية في النص.
⦁ التصنيف النصي (text classification): تصنيف المقالات الإخبارية، الإيميلات، أو التقييمات لفئات محددة.
BERT تفوق على كثير من ال models اللي قبله وحقق أرقام قياسية جديدة في مهام NLP كتير. قدرته على إنه يتعدل لاستخدامات مختلفة بتخليه أداة قيمة في مجالات متنوعة زي خدمة العملاء، الصحة، والمالية.
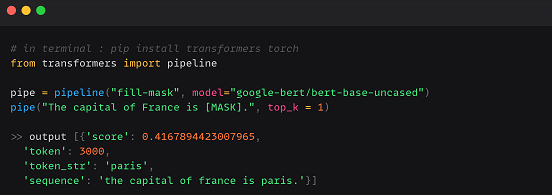
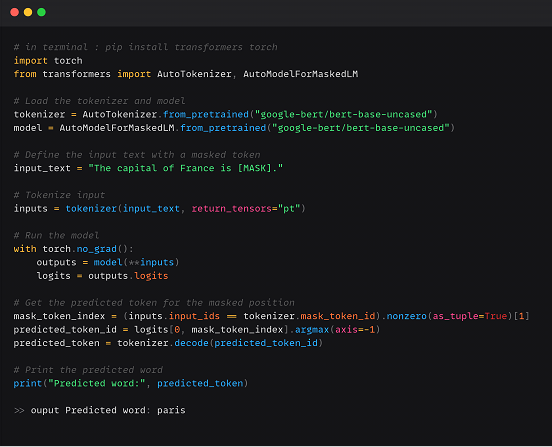
استخدم BERT من منصة Hugging Face :
عن طريق pipeline :
عن طريق AutoModel:
في الختام
BERT بيمثل نقلة نوعية في NLP بفضل استخدامه لبنية Bidirectional Transformer اللي بتتعلم العلاقات السياقية العميقة في اللغة. من خلال التدريب الأولي على dataeset ضخمة وبعدين التعديل النهائي على المهام المحددة، BERT أثبت قدرته على التعامل مع تحديات NLP المختلفة بأداء عالي. تأثيره بيكبر كل يوم مع انتشار تقنيات NLP في حياتنا اليومية.
فهم BERT وعملية تدريبه بيدينا فكرة عن تطور نماذج NLP، اللي بتسمح للآلات بمعالجة وفهم اللغة بشكل طبيعي أكتر من أي وقت فات. سواء كنت عايز تبني chat bot , customer sentiment analysis أو تحسن مشاريع ال NLP بتاعتك، بنية BERT وطريقة تدريبه بيوفروا أساس قوي لمواجهة المهام اللغوية المعقدة.
