



RAG

RAG
فهم Retrieval-Augmented Generation (RAG):
في عالم الذكاء الاصطناعي اللي بيتطور بسرعة، Retrieval-Augmented Generation (RAG) هو واحد من أحدث الابتكارات اللي بتغير طريقة توليد النصوص (Text Generation) من الآلات. الفكرة هي دمج قوة استرجاع المعلومات(Retrieval) مع (LLMs). يالا نبدا نشرحها بشكل بسيط عشان نفهم إزاي RAG بيشتغل وليه بيعتبر ثورة في هذا المجال.
إيه هو RAG؟
- Retrieval-Augmented Generation (RAG) هو طريقة بتحسن جودة النصوص اللي بتولدها ال(AI Models ) عن طريق استرجاع معلومات من مصدر خارجي (زي قاعدة بيانات أو مجموعة مستندات) ودمجها مع قدرة ال model على توليد نصوص(Text Generation). النتيجة هي ردود أكتر دقة وحديثة ومتوافقة مع الواقع من الذكاء الاصطناعي.
- على الرغم من إن (LLMs) زي GPT-3 و GPT-4 قادرة على توليد نصوص زي الانسان ويمكن افضل ، إلا إن في بعض الأحيان بتنتج محتوى مش دقيق أو قديم لأنها حصلها Train على بيانات قديمة. هنا بيجي دور RAG، اللي بيسمح لل model بالوصول لمصادر معرفية خارجية واستخدامها علشان تزود المحتوى اللي بتولده.
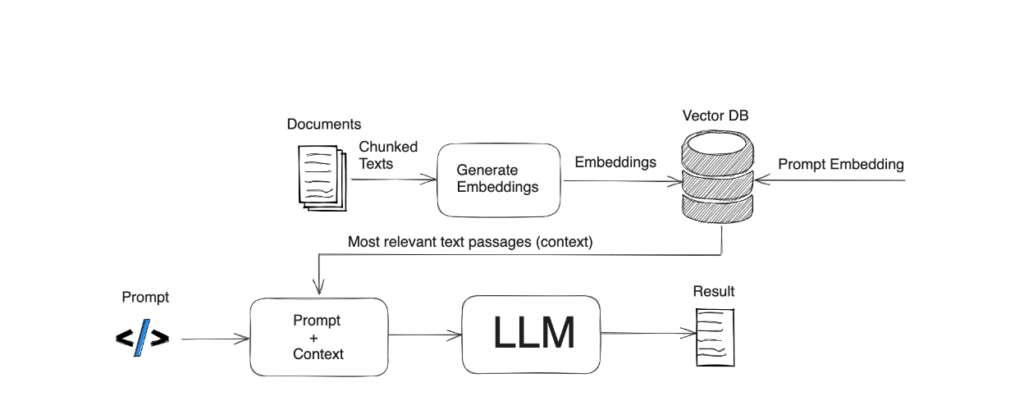
إزاي RAG بيشتغل؟
خلينا نفهم الموضوع بشكل أبسط:
⦁ الاسترجاع (Retrieval): أول خطوة، ال model بيبحث عن معلومات ويسترجع بيانات من مصدر معرفي أو قاعدة بيانات. ممكن تكون معلومات من مقالات علمية، أبحاث، أو أي مستندات تانية.
⦁التوليد (Generation): بعد ما ال modelيسترجع المعلومات دي، بيستخدمها عشان يولد رد أو نص جديد بناءً عليها.
مثال بسيط: لو سألت ال model عن أبحاث جديدة في موضوع “تغير المناخ”، بدلاً من الاعتماد على البيانات اللي اتدرب عليها ال model ، ال RAG هيسمح لل model بالبحث في المقالات الحديثة واسترجاع البيانات المناسبة عشان يضمن إجابة دقيقة وحديثة
ليه نستخدم RAG؟
RAG مفيد لأنه بيجمع بين حاجتين قويتين في الذكاء الاصطناعي:
⦁ استرجاع المعلومات (Information Retrieval): ال model بيقدر يبحث في قواعد بيانات ضخمة عشان يلاقي المعلومات المناسبة، ,وده الي بيخلي الإجابات أكتر دقة.
⦁ توليد النصوص(Text Generation): بعد ما بيسترجع المعلومات دي، الmodel بيولد نصوص تشبه النصوص اللي بيكتبها البشر بناءً على البيانات دي.
التكامل: ده بيضمن إن النص اللي بيتولد مش بس مبدع، لكن كمان معتمد على معلومات حقيقية وذات صلة.
تطبيقات RAG:
⦁ إنشاء المحتوى: الكتاب والمبدعين في المحتوى يقدروا يستخدموا RAG عشان يسترجعوا بيانات من مصادر مختلفة ويولدوا مقالات أو تقارير بسرعة ودقة.
⦁ المساعدة التعليمية: الطلاب والمعلمين يقدروا يستخدموا RAG في أبحاثهم أو كتابة المقالات الدراسية عشان يضمنوا إن المعلومات حديثة ودقيقة.
⦁ دعم العملاء: الروبوتات الذكية والـ chatbots المدعومة بـ RAG تقدر توفر إجابات دقيقة على استفسارات العملاء من خلال استرجاع المعلومات وتوليد ردود مخصصة.
⦁ اكتشاف المعرفة: الباحثين والعلماء ممكن يستخدموا RAG علشان يستعرضوا كميات ضخمة من البيانات والمراجع ويكتشفوا أفكار جديدة تساعد في تقدم الأبحاث.
إزاي بيتم بناء نماذج RAG؟
- قواعد بيانات المتجهات (Vectors Database): دي قواعد بيانات تخزن المعلومات على هيئة متجهات (Vectors). ده بيساعد النموذج )(model)في البحث عن أكتر المعلومات صلة بالاستفسار.
- نماذج اللغة الكبيرة (LLMs): بعد ما النموذج يسترجع البيانات، بيستخدمها لتوليد نصوص(Text Generation) بشرية بناءً على السياق اللي اتقدم له.
- الmodel :ده عادة بيشملVector Database بيخزن Vector Representation للنصوص، وعندما بيتم تقديم استفسار، النظام بيبحث عن أكتر البيانات صلة باستخدام التشابه بين الاستفسار والبيانات المخزنة.
الاعتبارات الأخلاقية في RAG:
رغم إن RAG بيقدم فوائد كتير، لكن لازم ناخد في الاعتبار الجوانب الأخلاقية:
⦁ التحيز والعدالة: النماذج (models) اللي اتدربت على بيانات منحازة (bias) ممكن تسترجع معلومات منحازة كمان، وده ممكن يؤثر على دقة المحتوى المولد. لازم نتأكد من العدالة في البيانات المسترجعة والنصوص المولدة.
⦁ الخصوصية والأمان: لما ال model يسترجع بيانات من قواعد بيانات ضخمة، لازم نكون حذرين عشان ما يحصلش انتهاك لخصوصية البيانات، خصوصًا لو كانت بيانات حساسة.
⦁ الشفافية: مهم جدًا إننا نفهم إزاي ال model بيسترجع المعلومات وبيستخدمها في توليد النص. الشفافية دي بتزيد الثقة في النظام.
مشاريع مفتوحة المصدر لـ RAG:
فيه مشاريع مفتوحة المصدر بتخلي RAG أكثر سهولة وقابلية للتخصيص:
⦁ Hugging Face’s Transformers: بيقدم تنفيذ بسيط لـ RAG باستخدام models زي T5 أو BART لاسترجاع وتوليد النصوص.
⦁ REALM: مكتبة متقدمة بتستخدم آليات الانتباه(attention mechanism ) لتحسين دقة استرجاع البيانات ورفع مستوى الاتساق الواقعي في النصوص المولدة.
⦁ LangChain: مكتبة مرنة تسمح ببناء خطوط أنابيب(pipe lines) مخصصة لـ RAG باستخدام نماذج استرجاع وتوليد مختلفة.
⦁ LlamaIndex: مشروع بيركز على بناء أنظمة استرجاع فعالة وقابلة للتوسع باستخدام تقنيات زي FAISS (بحث تشابه الفيسبوك).
⦁ PrivateGPT: أداة ذكية خاصة بتسمح لك بالسؤال عن مستنداتك باستخدام models لغة متقدمة، مع ضمان خصوصية البيانات لأن مفيش حاجة بتروح على الإنترنت.
الخلاصة:
Retrieval-Augmented Generation (RAG) هو ثورة في مجال الذكاء الاصطناعي لأنه بيجمع بين البحث عن المعلومات وتوليد النصوص بطريقة تحسن دقة وجودة النصوص اللي بتولدها الآلات. ده بيخلي النظام مش بس مبدع لكن كمان يعتمد على معلومات حقيقية وحديثة. مع تطبيقات في مجالات متعددة زي إنشاء المحتوى، المساعدة التعليمية، ودعم العملاء، RAG هيغير شكل العديد من الصناعات. لكن، لازم نكون حذرين في التعامل مع الجوانب الأخلاقية لضمان استخدامه بشكل مسؤول.
RAG لسه في تطور مستمر، وامكانياته هتزيد وتكبر مع تقدم تكنولوجيا الذكاء الاصطناعي.
