


Paddle OCR

Paddle OCR
introduction
في المقالة دي هنتكلم بالتفصيل عن PaddleOCR، وهي مكتبة مفتوحة المصدر بتشتغل على التعرف على النصوص من الصور (OCR). سواء كنت شغال على مشروع كبير زي معالجة المستندات والفواتير، أو بتدور على أداة تساعدك في استخراج النصوص من الصور العادية، PaddleOCR بتقدم حلول مميزة تجمع بين الدقة والسهولة. المكتبة دي جزء من منصة PaddlePaddle، اللي بتعتبر واحدة من أقوى منصات الذكاء الاصطناعي حاليًا.
الميزة الكبيرة في PaddleOCR إنها بتوفر أداء ممتاز وسهولة استخدام كبيرة جدًا. مع أدواتها الجاهزة وال models المدربة مسبقًا، أي حد يقدر يبدأ بيها بسهولة سواء كان مبتدئ أو محترف.
إزاي PaddleOCR بيشتغل
العملية بتتكون من كام مرحلة كل واحدة منهم ليها دور مهم في استخراج النص من الصورة. ده شرح سريع لخطوات الشغل بتاعها:
⦁ المعالجة المبدئية (image processing): قبل ما نبدأ استخراج النص، الصورة بتتعالج علشان جودتها تتحسن. المرحلة دي بتشمل تقليل الضوضاء، تحويل الصورة لأبيض وأسود (Binarization)، تكبير الصورة أو تصغيرها، وكمان تصحيح اتجاه النص لو كان مائل.
⦁ الكشف عن النص (Detection) : في المرحلة دي، PaddleOCR بيستخدم Deep Learning Model علشان يحدد أماكن النصوص داخل الصورة. ال model ده بيحدد مكان النص في الصورة ويعزله عن باقي الأجزاء. ال Detection model قادر يتعامل مع النصوص اللي مش مستوية أو مائلة، وده مهم في المستندات الممسوحة ضوئيًا أو الصور الواقعية.
⦁ التعرف على النص(Recognition): بعد ما يتم تحديد أماكن النصوص، بننتقل لمرحلة التعرف على النصوص. هنا PaddleOCR بيستخدم Deep Neural Network زي CRNN، وهي عبارة عن neural network تجمع بين الـ (CNN والـ RNN) علشان يقرأ الصورة ويحولها لنص. الnetwork دي بتحول المناطق اللي فيها النصوص لصيغة قابلة للفهم.
⦁ ما بعد المعالجة: بعد ما النظام يطلع النص، بيتم مراجعته وتصحيحه في المرحلة دي علشان يتحسن الدقة. ممكن تشمل المرحلة دي تصحيح للأخطاء الإملائية، إزالة رموز غير مرغوب فيها، وتنسيق النص عشان يبقى أقرب للترتيب الأصلي في المستند.
معمارية PaddleOCR
PaddleOCR بيستخدم مجموعة من المكونات الرئيسية في المعمارية بتاعته علشان يحقق دقة وكفاءة في مهام الـ OCR :
⦁ Network Backbone: ال network دي مسؤولة عن استخراج الخصائص من الصورة. الnetworks اللي بتستخدم عادة زي ResNet أو MobileNet، واللي هي (CNNs) بتقدر تلتقط التفاصيل الصغيرة في الصورة زي الحواف والأنماط.
⦁ شبكة الكشف عن النص (Detection Network): في PaddleOCR، بيتم استخدام model زي EAST (Efficient and Accurate Scene Text Detector) أو DB (Differentiable Binarization) علشان يحددوا الأماكن اللي فيها النص داخل الصورة ويعملوا تحديد للمناطق دي (Bounding Boxes) أو خرائط تقسيم النصوص (Segmentation Maps).
⦁ شبكة التعرف على النص (Recognition Network) : ال network دي بتعتمد على تصميم CRNN اللي بيجمع بين (CNN) لاستخراج الخصائص و (RNN) للتعرف على تسلسل النصوص. ال network دي بتقرأ النصوص الموجودة في المناطق اللي اتحددوا في المرحلة السابقة وبتطلع النصوص المطلوبة.
⦁ طبقة ما بعد المعالجة: الطبقة دي مسؤولة عن تحسين النتائج بعد ما يخلص التعرف على النص. ممكن تشمل تصحيح إملائي، دمج الأسطر أو تحسين الفهم الهيكلي للنص. الطبقة دي هي اللي بتخلي النص النهائي يكون مرتب وواضح.
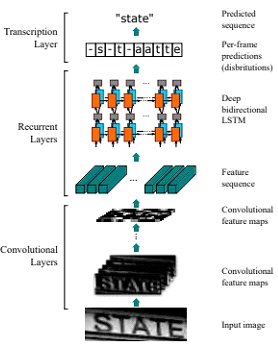
ليه تختار PaddleOCR؟
⦁ دعم متعدد للغات: واحدة من أكبر مميزات PaddleOCR إنها بتدعم أكتر من 80 لغة، وده بيشمل العربي، الإنجليزي، الصيني، وكمان لغات تانية كتير. الميزة دي بتخليها أداة عالمية فعلاً ومناسبة لمشاريع متنوعة.
⦁ أداء عالي: الأداء السريع والدقة العالية اللي بتقدمها المكتبة دي مبنية على تقنيات Deep Learning حديثة جدًا. وده بيفيد في المشاريع اللي بتحتاج سرعة في معالجة كمية كبيرة من الصور.
⦁ سهولة الاستخدام: المكتبة مناسبة جدًا لأي حد، حتى لو كنت لسه بتبدأ في مجال الذكاء الاصطناعي. بفضل الوثائق الجيدة والمجتمع الكبير اللي بيدعمها، هتلاقي كل حاجة جاهزة عشان تبدأ.
⦁ مرونة كبيرة: لو عندك احتياجات خاصة، PaddleOCR بتسمحلك تخصص ال model وتعدلها بسهولة. من أول التدريب على بياناتك الخاصة لغاية تعديل ال models الجاهزة.
⦁ مجتمع قوي وداعم: المجتمع اللي حوالين المكتبة دي مليان بالأفكار والمساهمات الجديدة. كمان التوثيق الشامل بيخليك تحل أي مشكلة ممكن تقابلك بسهولة.
إزاي تبدأ؟
1.تثبيت المكتبة
أول خطوة هي تثبيت المكتبة. لو معندكش Python مثبت، هتحتاج تبدأ بتنزيله. بعد كده، نفذ الأمر التالي:

لو بتستخدم GPU، تأكد إنك تنزل النسخة المناسبة من PaddlePaddle اللي بتدعم الـ GPU عشان تحسن الأداء لو شغال على مشاريع كبيرة.
2.أول تجربة ليك مع PaddleOCR
خلينا نجرب كود بسيط يوضح إزاي تقدر تبدأ مع المكتبة:
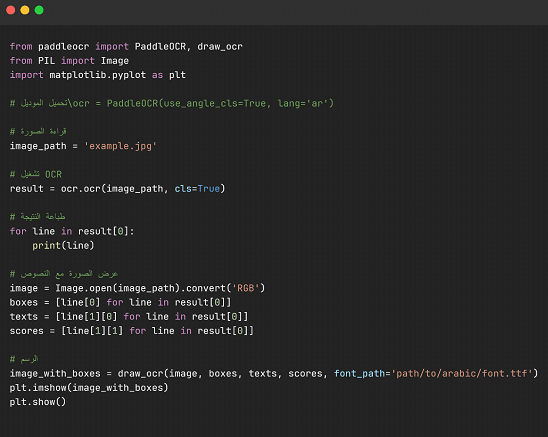
3. تخصيص ال model حسب احتياجاتك
لو عندك بيانات خاصة مش متوافقة مع ال models الجاهزة، تقدر تدرب PaddleOCR على بياناتك بسهولة. المكتبة بتوفر أدوات لتجهيز البيانات، اختيار الmodel ، وضبط المعايير، وده بيخليك تبدأ التدريب بسرعة وفعالية.
4. التكامل مع مشاريعك
سواء كنت بتبني تطبيق ويب باستخدام Flask أو Django، أو تطبيق موبايل بـ Flutter، أو حتى تطبيق مكتبي باستخدام PyQt، PaddleOCR بتشتغل بسلاسة مع معظم التقنيات. ده بيوفرلك أداة قوية تقدر تضيفها لأي نظام بسهولة.
حالات الاستخدام
⦁ معالجة الفواتير والإيصالات: أتمتة استخراج البيانات من الفواتير بيوفر وقت وجهد كبيرين، وبيقلل من الأخطاء.
⦁ الوثائق القانونية: بدل ما تضيع وقت في البحث داخل المستندات الورقية، ممكن تستخدم المكتبة لتحويلها لنصوص رقمية سريعة البحث.
⦁ التعليم: رقمنة الكتب والملاحظات بتسهل نشر وتعديل المحتوى التعليمي بشكل كبير.
⦁ التحليلات التجارية: استخراج البيانات من تقارير الأعمال وتحليلها بشكل أسرع بيساعد أصحاب القرار ياخدوا قرارات مبنية على بيانات دقيقة.
⦁ الأبحاث العلمية: بدل ما تكتب البيانات يدويًا من الأوراق العلمية، المكتبة بتسهل عليك العملية دي بشكل كبير.
⦁ تطبيقات ذكية: لو بتبني تطبيق ترجمة فوري أو نظام مساعدة بصرية، PaddleOCR هتكون أداة لا غنى عنها.
نصائح لتحسين تجربتك مع المكتبة
⦁ استخدم صور بجودة عالية عشان تحصل على دقة أفضل.
⦁ جرب ال models الجاهزة المختلفة وشوف الأنسب لبياناتك.
⦁ لو بتشتغل على اللغة العربية، تأكد من استخدام خطوط متوافقة عند الرسم على الصور.
⦁ شارك مشاكلك وأفكارك مع مجتمع المستخدمين، دايمًا هتلاقي حلول ودعم.
الخلاصة
PaddleOCR بتقدم مزيج رائع من الدقة، السرعة، وسهولة الاستخدام، وده بيخليها اختيار مثالي لأي مشروع OCR. مع دعمها للغة العربية ومرونتها الكبيرة، المكتبة دي تقدر تخليك تحل مشاكل كتير بطرق مبتكرة وسريعة. جربها بنفسك وشوف قد إيه هتضيف لمشاريعك قيمة حقيقية. ولو احتجت أي مساعدة، المجتمع موجود والدعم متوفر.
