


Transformers

Transformers
في هذه المقالة هنتكلم عن ال Transformers models والثورة الي عملتها في مجال الذكاء الاصطناعي
في السنين الأخيرة، ظهرت تقنية قوية في مجال تعلم الآلة (machine learning) اسمها ال transformers، وهي بقت أداة أساسية في معالجة اللغة الطبيعية (NLP). النماذج (models) دي اتصممت في البداية عشان تفهم وتنتج اللغة، بس بقت تستخدم في مجالات تانية زي الترجمة، تلخيص النصوص، وحتى معالجة الصور. في المقالة دي، هنشرح إزاي ال (Transformers) بيشتغل، إيه اللي بيميزه، وإزاي بيقدر يساعد في تطبيقات الذكاء الاصطناعي النهارده. في الآخر، هتكون فاهم كويس ليه ال (Transformers) مهم في تطوير الذكاء الاصطناعي.
ليه محتاجين الTransformers؟
قبل ال transformers، ال models التقليدية في معالجة اللغة زي الشبكات العصبية التكرارية (RNNs) والشبكات اللي بتستخدم الذاكرة الطويلة (LSTMs) كانت بتشتغل بشكل متتالي، يعني كل كلمة تتعالج لوحدها. ال models دي كانت بطيئة ومش بتقدر تحتفظ بالسياق اللي موجود في جمل طويلة، وده بيخليها مش دقيقة قوي.
في سنة 2017، باحثين في جوجل قدموا تقنية ال transformers في بحث بعنوان “Attention is All You Need” واللي غير كتير في معالجة اللغة. التقنية الجديدة دي اعتمدت على “آلية الانتباه” (attention mechanism )اللي بتخلي النموذج (model) يقدر يشوف كل الكلمات في الجملة مرة واحدة، وده بيخليه أسرع وأكتر دقة.
نظرة عن قرب عن Transformer Model :
عشان نفهم ليه ال Transformers ليه قوي، خلينا نشرح المكونات الأساسية وازاي كل جزء بيساعده في فهم اللغة:
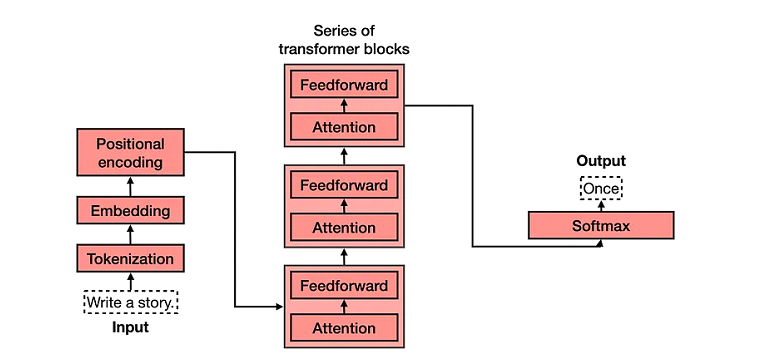
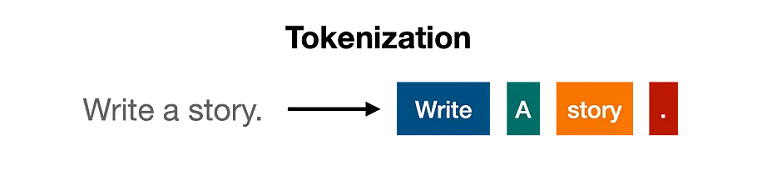
تقسيم النص: تحويل الكلمات لرموز
أول خطوة في معالجة النص باستخدام ال Transformer هي تقسيم النص لرموز (Tokens)، يعني بيقسم الجملة أو النص لأجزاء أصغر. كل جزء بيبقى رمز (token) (ممكن يكون كلمة أو جزء من كلمة). زي جملة “القطة نائمة”، ممكن تتقسم ل tokens زي [“القطة”, “نائمة”] كده عندنا 2 tokens.
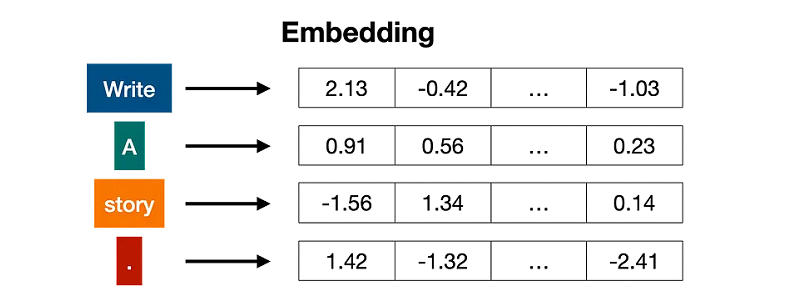
الترميز (Embedding): تحويل الرموز لأرقام
بعد تقسيم النص، كل token بيتحول لمجموعة أرقام بتعبر عن معناه وعلاقاته مع أل tokens التانية. العملية دي اسمها “Embedding”. ال embedding بيساعد الmodel يفهم العلاقات بين الكلمات، زي ان “قطة” و”كلب” يكونوا قريبين في المعنى.
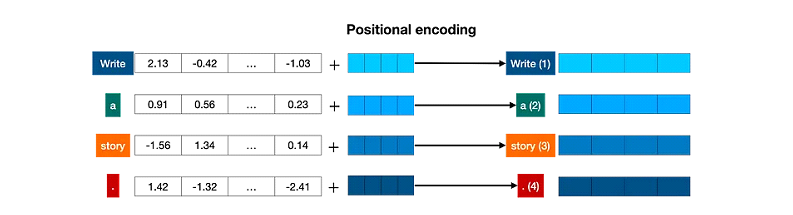
ترميز الموقع (positional encoding): الحفاظ على ترتيب الكلمات
عشان ترتيب الكلمات مهم لفهم المعنى، الmodel بيستخدم “ترميز الموقع” او Positional Encoding اللي بيضيف أرقام بتميز كل كلمة حسب ترتيبها في الجملة، وده بيساعد الmodel يحافظ على التركيب الأصلي للجمل.
ال Transformers Block :
بعد تجهيز الرموز والترميز، الرموز بتمر في طبقات متعددة من الtransformers block . كل block فيه مكونين رئيسيين بيساعدوا ال model يفهم اللغة:
⦁ آلية الانتباه متعددة الرؤوس (Multi-head attention)
⦁ شبكة عصبية أمامية (Feedforward Neurol Network)

آلية الانتباه متعددة الرؤوس (multi head attention): اكتشاف العلاقات بين الكلمات
آلية الانتباه (attention mechanism )هي سر قوة ال transformers. الmodel بيقدر يركز على الكلمات اللي ليها علاقة مع بعضها في الجملة، وده بيساعده يفهم السياق. مثلا في جملة “القطة نائمة على السرير”، ال attention ممكن يخلي الmodel يركز على العلاقة بين “القطة” و”نائمة”.
ميزة “متعددة الرؤوس” (multi head attention) بتخلي الmodel يقدر يعالج الجملة من زوايا مختلفة في نفس الوقت، وده بيزود الفهم العميق للجملة.
الشبكة العصبية الأمامية (feedforward neural network): التوقعات الدقيقة
بعد مرحلة ال attention، البيانات بتدخل في feedforward neural network اللي بتساعد في ترجمة المعلومات اللي ال model جمعها لمفاهيم واضحة تساعد في التوقعات النهائية للmodel.
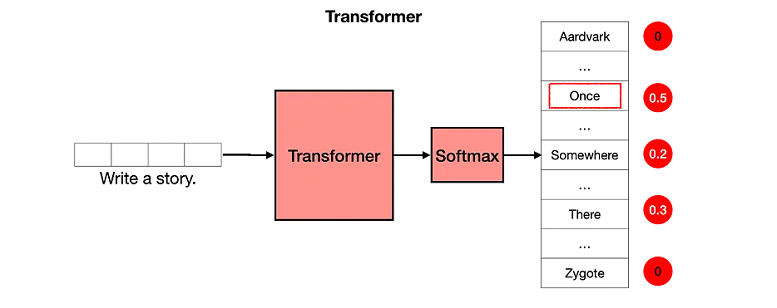
طبقة الاختيار (softmax layer): اختيار الكلمة الصحيحة
في الآخر، ال transformer بيستخدم طبقة اسمها “Softmax” عشان يختار الكلمة المناسبة. دي بتدي كل كلمة درجة احتمال، والاختيار بيقع على الكلمة اللي ليها أعلى احتمال.
إزاي الtransformers بيتعلم: التدريب والتخصيص
عشان الtransformer يقدر يفهم اللغة، لازم يتدرب على كميات كبيرة من النصوص. خلال التدريب، الmodel بيتعرض لكتير من الأمثلة عشان يتعلم قواعد اللغة وأنماطها. بس التدريب العام مش بيكون كافي دايما، وده بيخلي التخصيص مهم، خصوصًا لو الmodel هيشتغل في مجالات معينة زي الطب أو خدمة العملاء.
تطبيقات الtransformer في الحياة العملية
ال transformer غير كتير في مجالات متعددة، مش بس في معالجة اللغة. بعض التطبيقات المشهورة:
⦁ توليد النصوص (Text Generation): الtransformer بتستخدم في ال chatbots عشان ترد على الأسئلة بشكل طبيعي، زي ChatGPT.
⦁ الترجمة (translation): ال transformer حسّن كتير من دقة الترجمة زي google translate.
⦁ تلخيص النصوص(text summarization): بيساعد في اختصار النصوص الطويلة، زي تلخيص الأخبار أو التقارير.
⦁ التعرف على الكلام (speech recognition): زي اللي بنشوفه في Siri وAlexa..
مستقبل الtransformer : الابتكارات والإمكانيات
من وقت ظهوره، الtransformer بيتطور بسرعة. في models جديدة زي GPT-4 وBERT بقت بتقدم إمكانيات متطورة. الابتكارات المستمرة بتخليه أسرع وأقل في تكلفة الحسابات، وده بيزود من انتشاره.
الخلاصة
الtransformer غير مجال machine learning، وبيقدم إطار عمل قوي لتطبيقات الذكاء الاصطناعي الحديثة. ال models دي مش بس بتقدر تفهم اللغة، لكنها كمان بتتطور بسرعة في مجالات تانية.
